![]()
Published February 24, 2015 by Scott Allen Burns
Summary
The monomial method is an iterative technique for solving equations. It is very similar to Newton’s method, but has some significant advantages over Newton’s method at the expense of very little additional computational effort.
In a nutshell, Newton’s method solves nonlinear equations by repeatedly linearizing them about a series of operating points. This series of points usually converges to a solution of the original nonlinear system of equations. Linearized systems are very easy to solve by computer, making the overall process quite efficient.
 where the coefficient,
where the coefficient,  and the exponents,
and the exponents,  are all real-valued quantities, such as
are all real-valued quantities, such as  Contrast this to a linear expression,
Contrast this to a linear expression,  such as
such as 
The monomial method, in contrast, generates a series of monomial approximations (single term power functions) to the nonlinear system. In some applications in science and engineering, the monomial approximations are better than the linear approximations, and give rise to faster convergence and more stable behavior. Yet, when transformed through a simple change of variables into log space, the monomial approximation becomes linear, and is as easy to solve as the Newton approximation!
This presentation is written for someone who has learned Newton’s method in the past and is interested in learning about an alternative numerical method for solving equations. If this doesn’t match your background, you’ll probably not find this writeup very interesting! On the other hand, there may be some interest among those who fancy my artistic efforts because this topic is what first led me into the realm of basins of attraction imagery and ultimately to the creation of my Design by Algorithm artwork.
Newton’s Method
Newton’s method finds values of  that satisfy
that satisfy  In cases where cannot be solved for directly, Newton’s method provides an iterative procedure that often converges to a solution. It requires that the first derivative of the function,
In cases where cannot be solved for directly, Newton’s method provides an iterative procedure that often converges to a solution. It requires that the first derivative of the function,  be computable (or at least be able to be approximated).
be computable (or at least be able to be approximated).
It also requires an initial guess of the solution. That value, or “operating point,” gets updated with each iteration. In this presentation, I’ll be denoting the operating point with an overbar,  Any expression that is evaluated at the operating point is similarly given an overbar, such as
Any expression that is evaluated at the operating point is similarly given an overbar, such as  or
or 
![\[f(\bar{x}+\Delta x) = \bar{f} + \bar{f'}\,\Delta x \;+\;\bar{f''}\,(\Delta x)^2/2 \;+\;\bar{f'''}\,(\Delta x)^3/6 + \dots\;\]](https://quicklatex.com/cache3/65/ql_36cad5df7785e6667c4c860a1a875865_l3.png "Rendered by QuickLaTeX.com")
A linear approximation of the function is simply the first two terms:  We want the function to equal zero, so we set the linearized function equal to zero and solve for
We want the function to equal zero, so we set the linearized function equal to zero and solve for  yielding
yielding  Since is really the change in the operating point,
Since is really the change in the operating point,  we get
we get  which is Newton’s method.
which is Newton’s method.
The expression for computing a new operating point from the current one by Newton’s method is  Note that if we’re sitting at a solution,
Note that if we’re sitting at a solution,  the new operating point will be the same as the old one, meaning the process has converged to a solution.
the new operating point will be the same as the old one, meaning the process has converged to a solution.
Newton’s method isn’t guaranteed to converge. Note that if  the new operating point will be undefined and the process will fail. It’s also possible for the sequence of operating points to diverge or jump around chaotically. In fact, this undesirable characteristic of Newton’s method is responsible for creating some desirable fractal imagery! When Newton’s method misbehaves, it is often possible to reëstablish stable progress toward a solution by simply restarting from different operating point.
the new operating point will be undefined and the process will fail. It’s also possible for the sequence of operating points to diverge or jump around chaotically. In fact, this undesirable characteristic of Newton’s method is responsible for creating some desirable fractal imagery! When Newton’s method misbehaves, it is often possible to reëstablish stable progress toward a solution by simply restarting from different operating point.
It’s important to recognize that Newton’s method will solve a linear equations in exactly one iteration. Since Newton’s method is essentially a repeated linearization of the original problem, a linearization of a linear equation is just the original equation, so the first linear solution provided by Newton’s method IS the solution of the original problem. It will be seen later that the monomial method can be interpreted as Newton’s method applied to a reformulation (or transformation) of the original equation in such a way that the reformulated equation is often very nearly a linear expression, which Newton’s method solves easily.
Multiple Variables
 and
and  are column vectors, so the matrix multiplication works correctly. Also, this multivariate version of Newton’s method is sometimes called the “Newton-Raphson” method, but that terminology is becoming less common.
are column vectors, so the matrix multiplication works correctly. Also, this multivariate version of Newton’s method is sometimes called the “Newton-Raphson” method, but that terminology is becoming less common.So far, the expressions for Newton’s method have been presented for the case of a single variable and a single equation. It is also applicable to a system of simultaneous equations containing functions of multiple variables. For most problems, the number of equations in the system must equal the number of variables in order for a solution to be found. If we call a vector of variables,  and a vector of functions,
and a vector of functions,  then Newton’s method can be expressed as
then Newton’s method can be expressed as
![\[X_{new} = \bar{X} - \bar{J}^{-1}\;\bar{F},\]](https://quicklatex.com/cache3/5c/ql_7135d7a2d1eda7f8144789a6d0fbfa5c_l3.png "Rendered by QuickLaTeX.com")
where  is the Jacobian matrix of first partial derivatives and the bar above any quantity means that it is evaluated at the operating point. Each iteration requires the solution of a system of linear equations, which again is relatively easy for a computer to do.
is the Jacobian matrix of first partial derivatives and the bar above any quantity means that it is evaluated at the operating point. Each iteration requires the solution of a system of linear equations, which again is relatively easy for a computer to do.
An Example
Here is a system of equations in two variables:  and
and  It has four solutions,
It has four solutions,  Newton’s method for this system is
Newton’s method for this system is
![\[\left\{\begin{array}{c}x_{new}\\y_{new}\end{array}\right\} = \left\{\begin{array}{c}\bar{x}\\\bar{y}\end{array}\right\} - \left[\begin{array}{cc}4\;\bar{x}^3-12\;\bar{x}\;\bar{y}^2&-12\;\bar{x}^2\;\bar{y}+4\;\bar{y}^3\\12\;\bar{x}^2\;\bar{y}-4\;\bar{y}^3&4\;\bar{x}^3-12\;\bar{x}\;\bar{y}^2\end{array}\right]^{-1} \left\{\begin{array}{c}\bar{x}^4 - 6\;\bar{x}^2\;\bar{y}^2 + \bar{y}^4 - 1\\4\;\bar{x}^3\;\bar{y} - 4\;\bar{x}\;\bar{y}^3\end{array}\right\}\]](https://quicklatex.com/cache3/1d/ql_c63e6ac0d221259f2fd39f0a5cd8621d_l3.png "Rendered by QuickLaTeX.com")
There are many starting points that will cause this recurrence to fail, for example  But the vast majority of starting points will lead to convergence to one of the four solutions. Generally speaking, you will converge to the one closest to the starting point. But about 20% of so of the time, Newton’s method will converge to one of the other three more distant solutions. For example, starting with
But the vast majority of starting points will lead to convergence to one of the four solutions. Generally speaking, you will converge to the one closest to the starting point. But about 20% of so of the time, Newton’s method will converge to one of the other three more distant solutions. For example, starting with  the sequence of Newton’s method iterations are:
the sequence of Newton’s method iterations are: 



 and
and  This is an example of it converging to the nearest of the four solutions. However, starting with
This is an example of it converging to the nearest of the four solutions. However, starting with  Newton’s method gives:
Newton’s method gives: 







 and
and  In this case, it goes to the third most distant solution. Is there any regularity to this behavior?
In this case, it goes to the third most distant solution. Is there any regularity to this behavior?
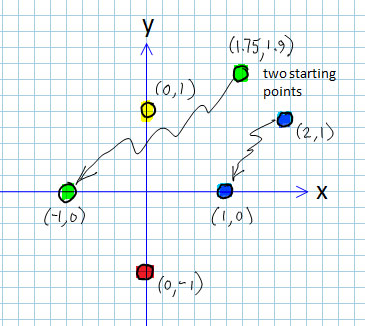
Making a color-coded summary of which starting points go to which solutions.
One way to visualize the overall behavior of an iterative process in two variables is to construct what is known as a “basins of attraction” plot. We start by assigning colors to each of the four solutions, as shown in this figure. Then we run Newton’s method from a large number of different starting points, and keep track of which starting points go to which solutions. The starting point location on the plot is colored according to the solution to which it converged. The final result is a color-coded summary of convergence.

The cover story on the Feb 1987 issue of Science News. (Click to enlarge.)
The result of this process is the image shown on the cover of Science News from 1987. (This was probably my first “15 minutes of fame,” back when fractals were brand new.) Notice that there are large red, green, yellow, and blue regions that are regions of starting points that all go to the same solution. On the diagonal, however, the colored regions are tightly intermingled, indicating that very tiny changes in starting point can lead to drastic changes in the outcome of Newton’s method. This “sensitive dependence to initial conditions” is a hallmark of chaotic behavior, and it captured graphically in the basins of attraction images.
You might be wondering about the different shades of each color. I selected the coloring scheme to reflect the number of iterations it took to get to a solution (to within some pre-defined tolerance). The colors cycle through six shades of each hue, from dark to light and over again, with increasing iteration count. Thus, the dark circles around each of the four solutions contain starting points that all converge to the solution in one iteration of Newton’s method. The slightly less dark region around each of them converge in two iterations, and so forth.
The “boundary” of each color is an extremely complex, fractal shape. In fact, it can be demonstrated that all four colors meet at every point on the boundary!

Prof. Arthur Cayley’s paper on the difficulty of describing the behavior of Newton’s method in some cases.
Although fractal images are a relatively recent concept, mathematicians have had glimpses of this behavior for a long time. In the 1800s, Professor Arthur Cayley of Cambridge was studying the behavior of Newton’s method with some very simple equations and found that it was quite difficult to state general rules for associating which starting points end up at which solutions. He wrote a one page paper on the subject in 1879 (shown in the figure). He compared the stable, easy to describe behavior of Newton’s method applied to a quadric (second order equation) to the case of a cubic equation, and observed the latter “appears to present considerable difficulty.” The Science News image above is the case of a fourth-order equation, one degree above the cubic that he considered. The difficulty he was talking about is the behavior in the regions of tightly intermingled colors, where the shapes of those regions defy description.
You might be wondering about the phrase “Newton-Fourier Imaginary Problem.” First the Fourier part: I’m not sure why Cayley is discussing Fourier in this paper. The Newton-Fourier method is known today as a process different from Newton’s method because it adds some additional computation to each step that can improve convergence. But the method he demonstrates in his paper is clearly the basic Newton’s method as I’ve described above.
Regarding the “imaginary” part, he was actually looking at Newton’s method operating on functions of a complex variable, that is, one that contains a real component and an imaginary component containing the imaginary quantity  The letter
The letter  is usually used to denote a complex variable, i.e.,
is usually used to denote a complex variable, i.e.,  Consider the function
Consider the function  It has four solutions, just like the example I showed earlier. They are
It has four solutions, just like the example I showed earlier. They are 

 and
and  Newton’s method can be applied just as effectively to functions of a complex variable, and the iteration in this case would be
Newton’s method can be applied just as effectively to functions of a complex variable, and the iteration in this case would be
![\[z_{new} = \bar{z} - \left(\frac{\bar{z}^4 - 1}{4 \bar{z}^3}\right).\]](https://quicklatex.com/cache3/ab/ql_0879d86adfb00d421cc554c83b298eab_l3.png "Rendered by QuickLaTeX.com")
Interestingly, if a basins of attraction plot were to be made of Newton’s method applied to  on the complex plane (real and imaginary axes) instead of the
on the complex plane (real and imaginary axes) instead of the  plane, it would be identical to the image on the Science News cover!
plane, it would be identical to the image on the Science News cover!
Next, substitute  for and expand the fourth power to give
for and expand the fourth power to give  (Remember to substitute
(Remember to substitute  for every instance of
for every instance of  Finally, collect all terms that are real into one equation and all terms that are imaginary into another equation. Divide the
Finally, collect all terms that are real into one equation and all terms that are imaginary into another equation. Divide the  out of the second equation, and you’ll be left with the exact same system of equations that I presented earlier; they are equivalent to one another. In fact, the image on the Science News cover is the one on the complex plane, not on the plane!
out of the second equation, and you’ll be left with the exact same system of equations that I presented earlier; they are equivalent to one another. In fact, the image on the Science News cover is the one on the complex plane, not on the plane!
The Monomial Method
The monomial method is an equation solving technique that I developed back in the ’80s as part of my research activities at the Univ of IL. It grew out of my work in optimization theory, specifically a method known as geometric programming that uses monomial approximations extensively. I found that the monomial method was just as easy to apply as Newton’s method, but was able to solve certain problems in my field of study (civil engineering structures) far more quickly and stably than Newton’s method. I’ll be demonstrating this in an example later.
There are some limitations of the types of problems the monomial method will solve. First, all variables must be positive. There is a logarithmic transformation in the method that will fail if an operating point is not greater than zero. Second, the equations being solved must be algebraic in form, such as  All algebraic systems of equations can be cast in the general form
All algebraic systems of equations can be cast in the general form
![\[\sum_{i=1}^{t_k}c_{ik}\prod_{j=1}^nx_j^{a_{ijk}} = 0 \;\;\;k=1,2,\dots,n.\]](https://quicklatex.com/cache3/3e/ql_67adee7ccff631c9326d014e12bc5c3e_l3.png "Rendered by QuickLaTeX.com")
In each of the  equations, there are
equations, there are  terms, each of which has a coefficient, followed by a product of variables,
terms, each of which has a coefficient, followed by a product of variables,  each raised to a power,
each raised to a power,  The coefficients and exponents can be any real number (positive, negative, fractional, etc.).
The coefficients and exponents can be any real number (positive, negative, fractional, etc.).
Let’s define  to be the th term of the th equation, or
to be the th term of the th equation, or
![\[u_{ik} = c_{ik}\prod_{j=1}^nx_j^{a_{ijk}}.\]](https://quicklatex.com/cache3/4b/ql_8b6cc0025788c58d00479b4cf15da04b_l3.png "Rendered by QuickLaTeX.com")
Next, we group together all the terms with positive coefficients and those with negative coefficients and recast the system of equations as the difference of two sums of terms,  and
and  respectively:
respectively:
![\[F_k(X) = P_k(X) - Q_k(X) = \sum_{P\;terms}u_{ik} - \sum_{Q\;terms}u_{ik} = 0 \;\;\;\;\;k=1,2,\dots,n.\]](https://quicklatex.com/cache3/e6/ql_4f0e6658075d61451c7b6117913a4fe6_l3.png "Rendered by QuickLaTeX.com")
Note that the coefficients in  are positive due to the negative sign in the expression. One final manipulation is to bring
are positive due to the negative sign in the expression. One final manipulation is to bring  to the right side of the equation and divide it through, giving us the recast form of the system of equations
to the right side of the equation and divide it through, giving us the recast form of the system of equations
![\[\frac{P_k(X)}{Q_k(X)} = \frac{\sum\limits_{P\;terms}u_{ik}}{\sum\limits_{Q\;terms}u_{ik}} = 1 \;\;\;\;\;k=1,2,\dots,n.\]](https://quicklatex.com/cache3/09/ql_94ed18ffa8c5de1ff31cd1fa79ddbd09_l3.png "Rendered by QuickLaTeX.com")
I’m hoping to keep this presentation accessible to a wide audience, and I’m sure the math-speak above might be difficult to decipher. So I’ll translate it in the setting of an example with just one equation and one variable:
![\[12 x^4 - 6.2 x^2 + x^{-1.5} - 2.7 = 0\]](https://quicklatex.com/cache3/a5/ql_62892f25f4d4edb685a70277f85a21a5_l3.png "Rendered by QuickLaTeX.com")
Using the terminology above,  and
and  The recast form is
The recast form is
![\[\frac{12 x^4 + x^{-1.5}}{6.2 x^2 + 2.7} = 1.\]](https://quicklatex.com/cache3/0f/ql_4f38a58457add96f595d3ea58653be0f_l3.png "Rendered by QuickLaTeX.com")
So in other words, all those math symbols above simply mean “divide the positive terms by the negative terms and set it equal to 1.”
We now apply a process called condensation to  and
and  separately. Condensation is the process of approximating a multi-term expression with a single-term expression (also called a monomial). It does this using a famous relationship between the arithmetic mean and the geometric mean of a set of positive numbers
separately. Condensation is the process of approximating a multi-term expression with a single-term expression (also called a monomial). It does this using a famous relationship between the arithmetic mean and the geometric mean of a set of positive numbers
![\[\sum_i n_i \delta_i \geq \prod_i n_i^{\delta_i}.\]](https://quicklatex.com/cache3/c2/ql_e8425aa713ec4f89a0de676697d97bc2_l3.png "Rendered by QuickLaTeX.com")
The  are weights, or fractional numbers that sum to 1. When all the weights are equal, then the left side is the familiar arithmetic mean (average) of the numbers, and the right side is the less known geometric mean. For example, if
are weights, or fractional numbers that sum to 1. When all the weights are equal, then the left side is the familiar arithmetic mean (average) of the numbers, and the right side is the less known geometric mean. For example, if  and all
and all  the geometric mean is
the geometric mean is  and the geometric mean is
and the geometric mean is ![\sqrt[3]{4\times5\times6} = 4.932.](https://quicklatex.com/cache3/7d/ql_ce69e38a06f281e00fae6cb202f9147d_l3.png "Rendered by QuickLaTeX.com")
The inequality becomes more useful to us if we make the substitution  giving
giving
![\[\sum_i u_i \geq \prod_i \left( \frac{u_i}{\delta_i} \right)^{\delta_i}.\]](https://quicklatex.com/cache3/c1/ql_1401933d1151c6fc5d4b8b05a7f4bcc1_l3.png "Rendered by QuickLaTeX.com")
This is where the magic happens. Instead of thinking of the  as simple numbers, we can think of them as monomials, just as we’ve defined earlier:
as simple numbers, we can think of them as monomials, just as we’ve defined earlier:
![\[\sum_i c_i \prod_j x_j^{a_{ij}} \geq \prod_i \left(\frac{c_i}{\delta_i} \prod_j x_j^{a_{ij}} \right)^{\delta_i}.\]](https://quicklatex.com/cache3/a7/ql_a3ee60ad56813ac8e5628432dc98a0a7_l3.png "Rendered by QuickLaTeX.com")
OK, lots of math. But let’s step back here and see what we have. The left side of this expression is simply our familiar expression for or the positive or negative terms in an equation. The right side, after everything gets multiplied out, is simply a single term, a monomial, something like  This is a monomial approximation to the polynomial expression on the left. The monomial will exactly equal the polynomial when evaluated at the operating point, and will approximate its value at other values of
This is a monomial approximation to the polynomial expression on the left. The monomial will exactly equal the polynomial when evaluated at the operating point, and will approximate its value at other values of 
So now let’s complete the monomial method, first in words, and later with math. We start by condensing  and each to monomials. The ratio of two monomials is again another monomial, so
and each to monomials. The ratio of two monomials is again another monomial, so  is an expression setting a monomial equal to 1. Remember from high school math that the logarithm of a product of numbers is equal to the sum of the logarithms of the numbers (the basis of the slide rule, for those of you as old as I am). The log of this monomial equation becomes a linear equation, which is simple to solve, giving rise to the new operating point (after transforming back out of log space with the exponential function,
is an expression setting a monomial equal to 1. Remember from high school math that the logarithm of a product of numbers is equal to the sum of the logarithms of the numbers (the basis of the slide rule, for those of you as old as I am). The log of this monomial equation becomes a linear equation, which is simple to solve, giving rise to the new operating point (after transforming back out of log space with the exponential function,  ).
).
The one missing piece to the puzzle is how to handle the weights,  It’s pretty simple: they are calculated as the fraction that each term in or contributes to the total, when evaluated at the current operating point. See how this makes the sum of the
It’s pretty simple: they are calculated as the fraction that each term in or contributes to the total, when evaluated at the current operating point. See how this makes the sum of the  equal to 1?
equal to 1?
It’s time to continue our simple example above. We had and Let’s select an operating point of  which gives us these weights:
which gives us these weights:
![\[\delta_1^+=\frac{12\;(1.5)^4}{12\;(1.5)^4+(1.5)^{-1.5}}=0.991\;\;\;\delta_2^+=\frac{(1.5)^{-1.5}}{12\;(1.5)^4+(1.5)^{-1.5}}=0.009\]](https://quicklatex.com/cache3/b8/ql_e8ec376ac82a973bdbf62bfbdaba40b8_l3.png "Rendered by QuickLaTeX.com")
![\[\delta_1^-=\frac{6.2\;(1.5)^2}{6.2\;(1.5)^2+2.7}=0.838\;\;\;\delta_2^-=\frac{2.7}{6.2\;(1.5)^2+2.7}=0.162\]](https://quicklatex.com/cache3/21/ql_86e8b4c9ec7e0fff0eaa06b54dcc0d21_l3.png "Rendered by QuickLaTeX.com")
The +/- superscript on indicates if the term came from or  The monomial approximation to is
The monomial approximation to is
![\[\frac{\left(\left(\frac{12}{0.991}\right)^{0.991} x^{4\;(0.991)}\right)\left(\left(\frac{1}{0.009}\right)^{0.009} x^{-1.5\;(0.009)}\right)}{\left(\left(\frac{6.2}{0.838}\right)^{0.838} x^{2\;(0.838)}\right)\left(\left(\frac{2.7}{0.162}\right)^{0.162} \right)} = 1.463\;x^{2.276} = 1.\]](https://quicklatex.com/cache3/4b/ql_efcfd6ffecedd096efc53c7a3226534b_l3.png "Rendered by QuickLaTeX.com")
Taking the log of this gives  Solving for
Solving for  gives
gives  which leads to
which leads to  This is the new operating point, which completes one iteration of the monomial method. Additional iterations will yield the sequence
This is the new operating point, which completes one iteration of the monomial method. Additional iterations will yield the sequence 
 and a solution has been found.
and a solution has been found.
A Computationally Efficient Way
It is apparent from that last example that the monomial method seems to involve much more computation than Newton’s method. The Newton iteration is simply 

 which generates the series of operating points from
which generates the series of operating points from  :
: 





Although Newton’s method is converging more slowly, the number of computations necessary is far less, especially considering that raising a number to a fractional power takes much more internal computation on a computer than simple multiplication or division.
Fortunately, there is an alternate way to compute the monomial method iteration that is more on par with the computational effort required for Newton’s method. Without getting into the details of the derivation, which are available elsewhere, the monomial method iteration can be stated as the following matrix equation:
![\[A\;\Delta Z = -\ln \left(\bar{P}\;/\;\bar{Q}\right ),\]](https://quicklatex.com/cache3/91/ql_bf34f82352b3c42b01754515b6c4fa91_l3.png "Rendered by QuickLaTeX.com")
where  is the change in the log of
is the change in the log of 
 and the matrix
and the matrix  has as its
has as its  th column and th row the value
th column and th row the value
![\[A_{jk} = \sum_{P\;terms} a_{ijk}\;\delta_{ik}^+ - \sum_{Q\;terms} a_{ijk}\;\delta_{ik}^-.\]](https://quicklatex.com/cache3/cf/ql_8947123f50a635849be89e3340519ecf_l3.png "Rendered by QuickLaTeX.com")
For the single variable example earlier,  which when evaluated at the operating point
which when evaluated at the operating point  gives
gives  Since
Since  and
and  the right side of the equation is
the right side of the equation is  Solving for gives
Solving for gives  and therefore
and therefore  This version requires far less computation than the monstrous equation used earlier!
This version requires far less computation than the monstrous equation used earlier!
Let me restate the math expressions above in words. Recall that each term in and has an associated weight, To create the matrix, simply multiply each exponent, of each variable by the weight associated with the term in which it appears. Gather together these products by common variable and add or subtract the product according to whether the term is in or  respectively.
respectively.
Here’s a two-variable example to demonstrate:
![\[\frac{11664 x_1 x_2^{-4}+54x_1^2x_2^{-4}+21.6 x_1^{-2}}{10.8 x_1^4 x_2^{-4}+4.32}=1\;\;\;\;\frac{6998.4 x_1^4 x_2^{-7}+18x_1^4x_2^{-6}+8398x_2^{-3}}{12.96x_1^4x_2^{-4}+5.184} = 1.\]](https://quicklatex.com/cache3/c3/ql_a1e20e06b109d23ab25f93b0f20f10c3_l3.png "Rendered by QuickLaTeX.com")
Let’s identify the weights (shown in correspondence to their associated term) as
![\[\frac{\delta_{11}^+,\;\;\delta_{21}^+,\;\;\delta_{31}^+}{\delta_{11}^-,\;\;\delta_{21}^-}\;\;\;\;\frac{\delta_{12}^+,\;\;\delta_{22}^+,\;\;\delta_{32}^+}{\delta_{12}^-,\;\;\delta_{22}^-}.\]](https://quicklatex.com/cache3/ba/ql_2dceedd2a017299ff81acd8ee6325aba_l3.png "Rendered by QuickLaTeX.com")
The matrix will be computed as (rows are by equation and columns are by variable)
![\[A = \left[\begin{array}{cc}\delta_{11}^++2\delta_{21}^+-2\delta_{31}^+-4\delta_{11}^-&-4\delta_{11}^+-4\delta_{21}^++4\delta_{11}^-\\4\delta_{12}^++4\delta_{22}^+-4\delta_{12}^-&-7\delta_{12}^+-6\delta_{22}^+-3\delta_{32}^++4\delta_{12}^-\end{array}\right].\]](https://quicklatex.com/cache3/50/ql_e40474759fa6d99426060214b8c6d350_l3.png "Rendered by QuickLaTeX.com")
If we start with  the weights will evaluate as
the weights will evaluate as
![\[\frac{0.3008,\;\;0.0028,\;\;0.6964}{0.0040,\;\;0.9960}\;\;\;\;\frac{0.0013,\;\;0.00003,\;\;0.9986}{0.0040,\;\;0.9960}\]](https://quicklatex.com/cache3/14/ql_7f5177e7a3e1a17f5a14efa0d60b9714_l3.png "Rendered by QuickLaTeX.com")
and matrix will evaluate as
![\[A = \left[\begin{array}{cc}-1.1023&-1.1985\\-0.0105&-2.9895\end{array}\right].\]](https://quicklatex.com/cache3/2c/ql_722dc97a30a9a3b3af00875cb35b9f2c_l3.png "Rendered by QuickLaTeX.com")
After evaluating the right-hand side [ ], we have the linear system
], we have the linear system
![\[A = \left[\begin{array}{cc}-1.1023&-1.1985\\-0.0105&-2.9895\end{array}\right]\left\{\begin{array}{c}\Delta z_1\\\Delta z_2\end{array}\right\}=\left\{\begin{array}{c}-0.5810\\-0.4798\end{array}\right\},\]](https://quicklatex.com/cache3/af/ql_37e2425fe3c4736f20d0a20d700430af_l3.png "Rendered by QuickLaTeX.com")
which solves for  and
and  The new operating point becomes
The new operating point becomes  and
and 
Relationship Between Newton’s Method and the Monomial Method
Again, without delving into details that are available elsewhere, the monomial method applied to  can be shown to be equivalent to Newton’s method applied to
can be shown to be equivalent to Newton’s method applied to
![\[\ln\frac{P(e^z)}{Q(e^z)}=0.\]](https://quicklatex.com/cache3/19/ql_01fd01e0a949d2c8a4b9760bdeb37e19_l3.png "Rendered by QuickLaTeX.com")
Note that Newton’s method is operated in the space of  instead of in the space of
instead of in the space of 
Newton’s method in matrix form is  where is the Jacobian matrix of first partial derivatives. The monomial method can be expressed similarly in terms of partial derivatives as
where is the Jacobian matrix of first partial derivatives. The monomial method can be expressed similarly in terms of partial derivatives as
![\[\left [D_{\bar{P}}^{-1}\;\bar{J}_P\;D_{\bar X}-D_{\bar{Q}}^{-1}\;\bar{J}_Q\;D_{\bar X}\right ]\Delta Z = -\ln \left(\bar{P}\;/\;\bar{Q}\right ).\]](https://quicklatex.com/cache3/37/ql_429e3cc2ea4bc3d8a72cf379ef55dd37_l3.png "Rendered by QuickLaTeX.com")
 and
and  in this expression are the Jacobian matrices of the and functions, evaluated at the operating point. The
in this expression are the Jacobian matrices of the and functions, evaluated at the operating point. The  matrices are diagonal matrices (all zeros except the values on the main diagonal):
matrices are diagonal matrices (all zeros except the values on the main diagonal):  has the values of the operating point,
has the values of the operating point,  on the diagonal;
on the diagonal;  and
and  have the values of
have the values of  and
and  on the diagonal (and they are inverted, so the diagonals are just
on the diagonal (and they are inverted, so the diagonals are just  and
and  ).
).
Why Bother?
So it seems the monomial method requires a little more computation. What do we stand to gain?
The following example is what convinced me that I was on to something with the monomial method. It demonstrates that for some applications, the difference in behavior between the monomial method and Newton’s method can be striking. It is most clearly demonstrated by constructing basins of attraction plots, as we did earlier.
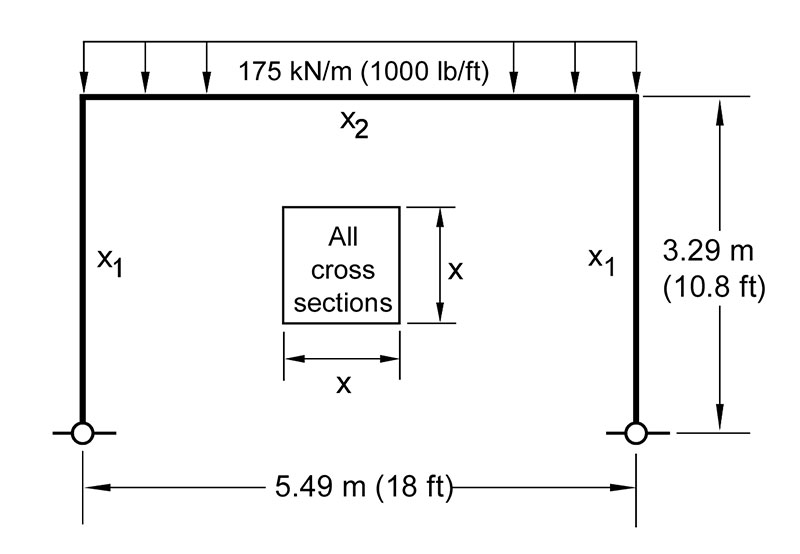
The design of a civil engineering frame structure comprising three members. (Click to enlarge.)
This example comes from the field of civil engineering structural design. One of the simplest frame structures, called a portal frame, has only three members, two vertical columns and a horizontal beam. The design goal is to select the dimensions of the members (the size of their square cross sections) so that the frame safely supports a load of 1000 pounds per foot along the beam. Assuming the two columns are of the same size, there are only two design variables,  and
and  that we seek to determine. Without getting into the engineering details, the example presented earlier
that we seek to determine. Without getting into the engineering details, the example presented earlier
![\[11664 x_1 x_2^{-4}+54x_1^2x_2^{-4}+21.6 x_1^{-2} - 10.8 x_1^4 x_2^{-4} - 4.32 =0\]](https://quicklatex.com/cache3/e1/ql_f59d85a0ec42074c4eb1ff02a4c877e1_l3.png "Rendered by QuickLaTeX.com")
![\[6998.4 x_1^4 x_2^{-7}+18x_1^4x_2^{-6}+8398x_2^{-3} - 12.96x_1^4x_2^{-4} - 5.184 = 0\]](https://quicklatex.com/cache3/af/ql_14c580aff4c4bb696f09a071fd4e8baf_l3.png "Rendered by QuickLaTeX.com")
are the governing equations for this example. In other words, values of and  that satisfy these equations are dimensions of the structure that we seek. These solutions are known as “fully-stressed designs” and can be thought of as particularly good designs because are safe and yet economical because they don’t unnecessarily waste building materials.
that satisfy these equations are dimensions of the structure that we seek. These solutions are known as “fully-stressed designs” and can be thought of as particularly good designs because are safe and yet economical because they don’t unnecessarily waste building materials.
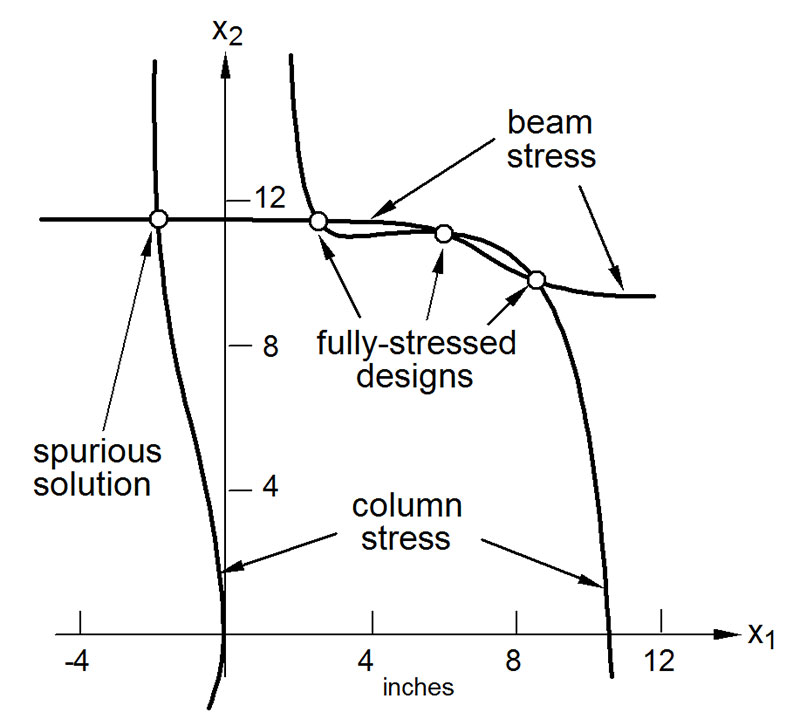
A plot of the two equations being solved. (Click to enlarge.)
We can plot the two equations on the  plane, as shown in the figure. The curve that runs more or less horizontally comes from one equation, whereas the two curves running vertically are two “branches” of the other equation. Since the equations are nonlinear, there are several solutions that satisfy them, shown as small circles where the curves intersect. Three of the four solutions fall in the positive quadrant of the “design space,” and represent physically realizable solutions. The fourth solution has a negative value for
plane, as shown in the figure. The curve that runs more or less horizontally comes from one equation, whereas the two curves running vertically are two “branches” of the other equation. Since the equations are nonlinear, there are several solutions that satisfy them, shown as small circles where the curves intersect. Three of the four solutions fall in the positive quadrant of the “design space,” and represent physically realizable solutions. The fourth solution has a negative value for  Although that point formally satisfies the equations, it is not a real solution because the square cross section cannot have a negative dimension. We call that a “spurious” solution.
Although that point formally satisfies the equations, it is not a real solution because the square cross section cannot have a negative dimension. We call that a “spurious” solution.
The three positive solutions have an interesting interpretation from an engineering point of view. The leftmost of the positive designs (with coordinates of approximately  and
and  ) has a heavy horizontal beam and relatively slender columns. This design resembles the ancient “post and lintel” type construction, where the beam does most of the work and the columns just prop up the ends of the beam without exerting too much effort. In contrast, the rightmost design has beam and column dimensions that are more similar. In this case, there are substantial forces being developed in the corners of the frame, and much of the load is carried by the bending action transmitted between the beam and the columns. It is a very different sort of load-carrying mechanism, one that is more recent in structural engineering practice with the advent of structurally rigid frame connections. I recall my PhD advisor, Narbey Khachaturian, telling me that the various solutions represent distinct load paths, or preferred ways that the frame likes to “flex its muscles.”
) has a heavy horizontal beam and relatively slender columns. This design resembles the ancient “post and lintel” type construction, where the beam does most of the work and the columns just prop up the ends of the beam without exerting too much effort. In contrast, the rightmost design has beam and column dimensions that are more similar. In this case, there are substantial forces being developed in the corners of the frame, and much of the load is carried by the bending action transmitted between the beam and the columns. It is a very different sort of load-carrying mechanism, one that is more recent in structural engineering practice with the advent of structurally rigid frame connections. I recall my PhD advisor, Narbey Khachaturian, telling me that the various solutions represent distinct load paths, or preferred ways that the frame likes to “flex its muscles.”
To create basins of attraction plots, we need to assign colors to the four solutions. Going from left to right, let’s select yellow, red, green, and blue. Let’s solve the equations using Newton’s method first. Here are the basins of attraction:
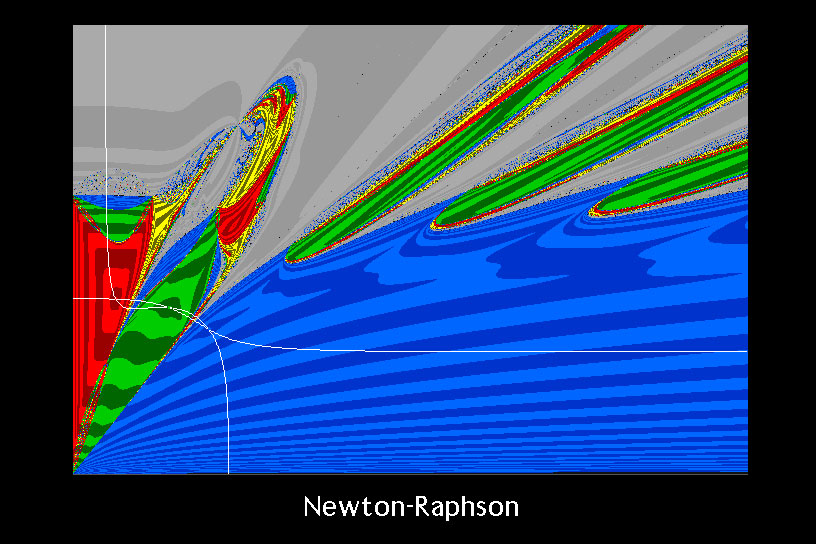
Basins of attraction for the frame example, as solved by Newton’s method. (I created this image decades ago, back when I was still calling it “Newton-Raphson.”)
I’m showing just the positive quadrant of the design space, and the curves are shown in white. The first thing you might notice is the large region of gray. That is a fourth color I selected to indicate when Newton’s method has failed, in this case, due to numerical overflow. In other words, any starting point in a gray region produced a series of operating points that just kept getting bigger and bigger until the computer could no longer represent the numbers and gave up with an error condition.
The two shades of each color represent whether the number of iterations it took to converge (or fail) was odd or even. Thus, the spacing of these stripes gives an indication of how fast the method converges (narrower stripes means slower).
Another interesting observation is all the yellow in the plot. These are starting points that end up at the spurious, meaningless solution, even though the process was initiated from a perfectly reasonable starting point. This is particularly troublesome. There are lots of places where very good initial designs, in the vicinity of the best designs, end up with useless results by Newton’s method!
Now let’s compare this to the monomial method:
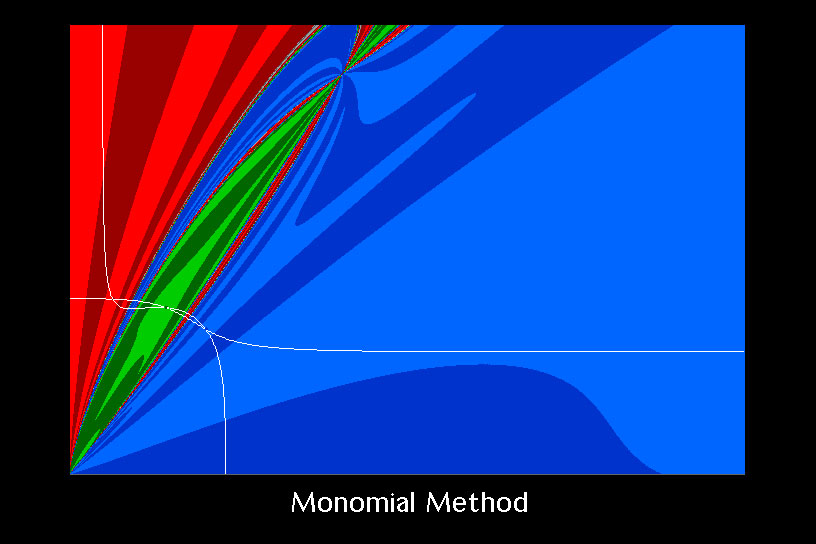
Basins of attraction for the frame example as solved by the monomial method.
What a world of difference! First of all, there are very few starting points that run into numerical difficulty. Second, the spacing between the stripes of color shades are much larger, indicating that convergence is happening very quickly, typically within just a few iterations instead of dozens. Third, and perhaps most importantly, no starting points end up at the meaningless solution (simply because the monomial method can’t converge there).
Special Properties
The monomial method exhibits some unusual properties, not shared by Newton’s method, that are responsible for the improved performance in certain types of applications.
- Multiplication of an equation by a positive polynomial has no effect on the monomial method iteration. With Newton’s method, it is often suggested that equations be put in some sort of “standard form” by multiplying through by powers of the variables. This can improve the performance of Newton’s method in some cases. There is no reason to manipulate the equations in this way for the monomial method. It will give the same sequence of operating points in all cases of this type of manipulation.
- There is an automatic scaling of variables and equilibrating of equations built into the monomial method. Newton’s method benefits greatly from these actions, but they must be done outside of, and in addition to, the regular Newton iteration. By examining the form of the monomial method involving Jacobian matrices (presented earlier), it can be seen that scaling and equilibrating are taking place automatically via the diagonal matrices that pre- and post-multiply the Jacobian matrices.
- The monomial method was shown to be equivalent to Newton’s method applied to expressions of the form
 When one term dominates the others, then the summation over effectively disappears and only the one term remains. The log and the exp functions cancel each other out, leaving just a linear expression,
When one term dominates the others, then the summation over effectively disappears and only the one term remains. The log and the exp functions cancel each other out, leaving just a linear expression,  Since Newton’s method applied to a linear expression gives a solution in just one iteration, the monomial method inherits this behavior.
Since Newton’s method applied to a linear expression gives a solution in just one iteration, the monomial method inherits this behavior. - When initiating the solution process from a very distant starting point, one term of each equation tends to dominate (assuming the terms in an equation have different powers of ) This makes the system appear to the monomial method as a nearly linear system, and initial iterations move very rapidly toward a solution, in contrast to Newton’s method, which can take dozens of iterations to recover from a distant operating point. This “asymptotic behavior” is evident in the frame example presented earlier. See this paper for details.
Connection to Artwork
The basins of attraction study I conducted at the University of Illinois in the late ’80s sparked my interest in creating abstract art using these methods, leading to my Design by Algorithm business. In particular, one of the early pieces I offered (image #34) was based on the frame example:

This is the frame example solved by another method called “steepest descent.” Can you see the three positive frame solutions? This image also appeared on the cover of a math textbook in the ’90s.
Although I’ve retired this image from the set of currently offered pieces, I have since cropped and rotated this image to form what is now known as Image 78:

The basins of attraction construction has been a fascinating “paintbrush” to work with over the past several decades. I have grown to where I can deliberately design math expressions for desired outcomes and express my artistic intent more fully.
________________________________________

Monomial Method by Scott Allen Burns is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
I purchased one of your artworks at the Flint Art Fair in 1995 – Design # 47. I really love that piece and would like to purchase a PDF of it to use as the photo on my desktop. Will you please send me information of how to do that? Thank you.